Stand: 25.12.2017, 15.06.2025
Jede Anwendung der hier beschriebenen Hinweise und Tips erfolgt ausschließlich auf eigene Gefahr. Keine Haftung für die Richtigkeit der Darstellung. Jegliche Haftung für irgendwelche Schäden aufgrund dieses Textes ist ausgeschlossen.
Vorwort: Ein Dialog aus "Star Wars: Andor", Staffel 1, Episode 5:
Nemik arbeitet an einem technischen Gerät.
Andor: "Ist'n altes Modell."
Nemik: "Alt, robust und zuverlässig. Eines der besten Navigationsgeräte, das je gebaut wurde.
Kann man weder stören, noch anpeilen.
Und wenn's mal kaputtgeht, reparierst Du's einfach."
Andor: "Schwer zu erlernen."
Nemik: "Ja, aber wenn man es beherrscht - ist man frei."
Ein Umstieg von Windows auf Linux bereitet vielen Leuten Schwierigkeiten, denn "Linux ist nicht Windows". Es gibt zwar viele Bücher zu dem Thema, aber diese Seite soll den Einstieg dadurch erleichtern, daß sie gerade die Dinge anspricht, die Windows-Benutzer an Linux am meisten verstören.
Windows ist ein Betriebssystem. Linux ist ein anderes Betriebssystem. Linux is also kein Programm für Windows.
Um die Unterschiede zwischen den beiden zu verstehen, ist es nötig, sich zunächst klarzumachen, wie Softwareentwicklung im allgemeinen abläuft, und was es mit "Freier Software" auf sich hat. Diese Themen werden einem Windows-Benutzer ziemlich seltsam erscheinen, aber es ist nötig, sich einmal damit auseinanderzusetzen, um zu verstehen, was Linux ist.
Computer können programmiert werden. Betriebssysteme sind Computerprogramme.
Der Kernel (also der Kern) von Windows und der Kernel von Linux wurden in einer Computersprache namens "C" geschrieben. Andere Teile von Windows wurden in einer Sprache namens "C++" geschrieben.
Der Computer kann C oder C++-Source-Code nicht direkt ausführen, sondern nur sogenannten "Maschinencode" Dieser besteht nur aus Zahlen, die in Bytes im Speicher abgelegt sind.
Man könnte zwar auch direkt Maschinencode schreiben (oder etwas abstrahiert Code in der Computersprache "Assembler"), aber das hätte einige Nachteile. So ist Maschinencode z.B. vom Prozessortyp abhängig. C-Source-Code dagegen ist bis zu einem gewissen Grade systemunabhängig.
Wenn also C verwendet wird, wird ein Programm benötigt, das C-Source-Code in Maschinencode (ausführbare Dateien, ".exe"-Dateien unter Windows) übersetzt. Ein solches Programm nennt man "Compiler".
Windows selbst enthält keinen C-Compiler, denn Microsoft sieht ein solches Programm als zusätzliche Anwendung, wie etwa Office.
Es gibt also einen C/C++-Compiler namens "Microsoft Visual C++", aber auch andere Produkte wie "Borland C++" oder den freien Compiler "gcc/g++", den man für Windows in einem Paket namens "MinGW" herunterladen kann.
Für Windows 10 stellt Microsoft inzwischen ein kostenloses Entwicklungspaket namens "Visual Studio Community" zur Verfügung.
Man kann C oder C++-Code einfach in einem Texteditor wie z.B. "Notepad" schreiben, aber mit einem Compiler erhält man meist ein spezielles Editor-Programm zur Softwareentwicklung. Ein solches Program nennt man "IDE" ("Integrated development environment"). Ein kleineres IDE wäre z.B. "Geany".
Dennoch schreiben viele Programmierer Code auch immer noch gern in Text-Editoren. Unter Linux gibt es insbesondere zwei sehr leistungsfähige. Der eine heißt "vim" (Windows-Version: "gVim"), der andere "Emacs".
Beide können sehr viel mehr als "Notepad" unter Windows, aber ihr Verhalten und die Tastaturbelegungen unterscheiden sich sehr von dem, was Windows-Benutzer gewohnt sind. Diese Webseite wurde mit vim geschrieben.
Wenn man also folgenden C-Source-Code in einer Text-Datei hat:
#include <stdio.h>
int main() {
puts("Hello World!");
return 0;
}
dann kann man den Compiler darauf anwenden, so daß er daraus eine ausführbare Datei "a.exe" erzeugt (ich habe auch eine Seite über C-Programmierung, aber das ist kein leichtes Thema).
Die Programmierer bei Microsoft schreiben den Source-Code für Windows. Microsoft kennt also diesen Code. Aber der Kunde, der Windows in einem Geschäft kauft, erhält nur die ausführbaren Dateien (und den Rest, den man benötigt, um Windows auszuführen). Microsoft gibt nicht den Source-Code mit heraus. Als Windows-Kunde kann man also weder den Source-Code lesen, noch ihn verändern. Man darf es nicht. Aber man erhält auch nicht die Gelegenheit dazu, weil Microsoft den Source-Code von Windows bei sich behält. Was ja auch nicht verboten ist.
Windows ist ein Produkt des Softwareunternehmens Microsoft.
Microsoft produziert es und vertreibt es über Geschäfte. Privatkunden kaufen es dort oder über das Internet. Sie bezahlen Geld dafür und erhalten als Gegenleistung einige Rechte.
Diese Rechte werden im einzelnen in einem "Endbenutzer-Lizenzvertrag" ("End-User License Agreement", EULA) vereinbart.
Wenn ein Kunde Windows kauft, darf er es natürlich auf einem einzelnen Computer installieren und benutzen.
Wahrscheinlich darf er es nicht zugleich auf einem zweiten Computer installieren.
Ich bin nicht ganz sicher, ob er seine Version an einen Dritten verkaufen darf, wenn er es von seinem eigenen Computer löscht. Vielleicht, vielleicht auch nicht.
Seit Windows XP muß der Kunde in Kontakt mit Microsoft treten und seine Windows-Version mit einem bestimmten Registrierungscode "aktivieren", so daß Microsoft kontrollieren kann, wie oft eine einzelne Windows-Version installiert wird.
Inzwischen (Windows 11) wird das Anlegen eines Microsoft-Benutzerkontos verlangt.
Der Kunde erhält nicht den Source-Code von Windows, so daß er ihn weder lesen, noch verändern kann. Microsoft Windows ist proprietäre, "Closed-Source"-Software.
Das ist wahrscheinlich die bekannte Situation, die der Kunde gewohnt ist.
Linux verfolgt in Bezug auf all diese Dinge einen völlig anderen Ansatz.
Und das kam so:
Es war einmal, in den 1970er Jahren, als ein Programmierer namens Richard Stallman in einem Rechenzentrum irgendwo in den USA arbeitete.
Da die Rechenleistung damals extrem gering und knapp war, mußten mehrere Programmierer an demselben Computer arbeiten.
Jede Person hatte ihren eigenen Arbeitsplatz und ihre eigene Tastatur (genannt "Terminal"), aber alle Tastaturen waren an einen einzigen Computer angeschlossen.
Diese Leute teilten sich auch die Software auf diesem Computer, und jeder, der es wollte, konnte den Source-Code lesen oder verändern.
Dann, eines Tages, kaufte das Rechenzentrum ein Programm eines externen Softwareunternehmens. Ähnlich wie Windows (das damals allerdings noch gar nicht existierte) handelte es sich um Closed-Source-Software. Also konnten die Mitarbeiter des Rechenzentrums (die Benutzer) seine Quellen nicht lesen oder das Programm verändern.
Immer mehr Unternehmen produzierten proprietäre Software, und immer mehr Programme, die nach diesem Prinzip produziert worden waren, wurden gekauft.
Richard Stallman war damit unzufrieden. Er wollte, daß Software wieder so sein sollte, wie er es vorher gekannt hatte, als jeder die Quellen lesen und verändern konnte.
Also wurde er Aktivist und gründete die "Free Software Foundation" ("Stiftung für Freie Software").
Diese Stiftung sagte: "Wirtschaftsunternehmen mögen proprietäre Software herstellen, aber wir stellen unsere eigene Art von Software her, Freie Software."
Im Deutschen kann man zwischen dem Wort "frei", also frei von Bindungen oder Zwängen, und dem Wort "kostenlos" unterscheiden. Der Ausdruck "Freie Software" bezieht sich auf die erste Bedeutung, also "frei" im Sinne von "Freiheit".
Das bedeutet zugleich, daß Freie Software nicht unbedingt kostenlos sein muß: Es kann sein, daß man sie von jemandem kauft, und dann für sie bezahlen muß.
Es war also das Anliegen der "Free Software Foundation", die Rechte des Computernutzers gegenüber den Herstellern von Hard- und Software zu stärken. Bei Freier Software sollte der Benutzer insbesondere vier Freiheiten haben. Der Benutzer sollte das Recht haben,
Proprietäre Software kann die Berechnungen, die auf dem Computer des Benutzers ablaufen, kontrollieren. Freie Software ermöglicht es dem Benutzer, seine eigenen Berechnungen selbst zu kontrollieren.
Die "Free Software Foundation" entwickelte eine Lizenz für diese Art Software, die dem Computerbenutzer diese vier Freiheiten (oder Rechte) gewährt, die "GNU General Public License" (GPL).
Es ist zu beachten, daß diese Lizenz dem Benutzer auch das Recht gibt, die Software gegen Geld zu verkaufen (als Teil des Rechtes, die Software weiterzugeben). Das bedeutet, obwohl man heute Freie Software an vielen Stellen im Internet kostenlos herunterladen kann, kann es sein, daß jemand anders versucht, einem die Software gegen Geld zu verkaufen, sei es in einem Geschäft oder im Internet. Nach der Lizenz ist er dazu berechtigt, und wenn man die Software von ihm kauft, muß man sie auch bezahlen.
Dann gründete die "Free Software Foundation" das "GNU Projekt", um selbst Freie Software zu entwickeln. Viele Kommandozeilenprogramme für ein Betriebssystem wurden geschrieben, aber auch solche Programme wie "GNU Chess". Richard Stallman schrieb den leistungsfähigen Editor "GNU Emacs".
Das GNU Projekt wollte ein vollständiges freies Betriebssystem entwickeln.
Aber der Kernel des GNU Projekts war noch nicht fertig, als Linus Torvalds 1991 mit einem Projekt begann, um seinen eigenen Kernel namens "Linux" zu entwickeln.
Viele Entwickler unterstützten Linus Torvalds über das Internet, das sich gerade entwickelte.
Der Kernel "Linux" wurde schließlich benutzbar, und man fügte die Systemwerkzeuge des GNU Projekts hinzu. Auf diese Weise wurde ein freies unixartiges Betriebssystem für Intel-Prozessoren fertiggestellt. Es sollte eigentlich GNU/Linux heißen, aber da nur "Linux" kürzer ist, nennen die meisten Leute es nur so. Der Linux-Kernel verwendet ebenfalls die "GNU General Public License" (GPL, Version 2).
Die Art und Weise, neue Software zu entwickeln, unterscheidet sich also bei beiden Modellen:
Die Ausbreitung des Internets hat die Entwicklung komplexerer Programme in drastischer Weise gefördert. "Linux ist ein Kind des Internets."
Aus dem oben Gesagten folgt, daß Entwickler proprietärer Software sehr daran interessiert sind, Marktanteile zu gewinnen. Sie möchten ihre Programme so oft wie möglich verkaufen, weil sie auf diese Weise ihr Geld verdienen.
Für Freie Software und ihre Entwickler haben Marktanteile dagegen überhupt keine Bedeutung.
Außerdem ist der Benutzer, der freie Software (insbesondere kostenlos) herunterlädt, niemandes Kunde.
"Der Kunde ist König" - Dieser Satz gilt möglicherweise für den Käufer proprietärer Software. Aber nicht für denjenigen, der Freie Software heruntergeladen hat.
Wenn ihm die Software nicht gefällt, wenn sie nicht das tut, was er von ihr erwartet, wenn er sie nicht noch einmal herunterladen würde, dann spielt das für die Freie Software einfach keine Rolle.
Freie Software steht nicht unter dem Zwang, gut auszusehen oder modern zu sein. Sie muß nicht am Markt bestehen. Es gibt für sie keinen Markt.
Wenn ein freies Programm so schlecht ist, daß niemand es benutzt, ist das dennoch ohne Bedeutung.
Das sollte man beachten, wenn man mit Linux umgeht. Man ist nicht Kunde (es sei denn, man bezahlt Unternehmen für Support-Dienstleistungen). Man ist daher nicht König. Man hat nur die vier Freiheiten (zu benutzen, zu lesen und zu verändern und die Software weiterzugeben (sei es kostenlos oder gegen Geld)).
Wenn einem ein Programm des GNU/Linux-Betriebssystems nicht gefällt, sollte man sich nicht beschweren, es hat keinen Sinn.
Es wäre an einem selbst, es besser zu machen. Wenn man das nicht kann, weil einem die dazu nötigen Kenntnisse oder die Zeit dazu fehlt, bleibt einem nur, das Programm nicht zu benutzen (bis jemand anders es vielleicht verbessert).
Nun sollte der Grund dafür klar geworden sein, warum viele freie Linuxprogramme bis zu einem gewissen Grade unfertig, unschön, altmodisch oder experimentell wirken, und daß das daran liegt, daß ihre Entwicklung nicht auf den Prinzipien des Kapitalismus beruhte.
Daß eine Software frei ist, bedeutet nicht notwendigerweise, daß sie technisch besser ist. Es kann gut sein, daß proprietäre Software eine Aufgabe besser erfüllt. Dennoch bleibt dabei das Problem, daß proprietäre Software bewirken kann, daß der Benutzer die Kontrolle über seinen Computer verliert, und daß sie ihn z.B. ausspioniert.
Oder wie Linus Torvalds es ausgedrückt hat: "Software is like sex: It's better when it's free."
Richard Stallman erklärt die Zusammenhänge von Freier Software (auf Englisch) hier.
In einem anderen Vortrag (an der Universität von Calgary (Kanada), 03.02.2009; auf Englisch) geht er zudem darauf ein, daß die Forderung nach den oben genannten "vier Freiheiten" sich nur auf Software beziehen könne, weil diese Freiheiten mit der Eigenart von Software zusammenhingen.
Nur bei kompilierter Software gibt es ein ausführbares Programm mit einem zugehörigen Source-Code, der gegebenenfalls zurückgehalten oder verändert werden kann. Nur Software und andere digitale Daten lassen sich leicht und schnell millionenfach kopieren und verbreiten.
Bei Sachen des täglichen Lebens wie etwa einem Tisch oder einem Stuhl ist das in der Form nicht der Fall. Ein Tisch selbst hat keinen Source-Code, und der Tisch selbst kann auch nicht ohne weiteres millionenfach kopiert werden. Es mag ein Fertigungsmuster (wie z.B. eine technische Zeichnung) für den Tisch geben, aber das wäre etwas anderes als der Tisch selbst.
Die Unausgewogenheit im Verhältnis zwischen Softwarehersteller und Softwarebenutzer und die Forderung nach den "vier Freiheiten" des Benutzers ist also eine Problematik, die es in dieser Form nur bei Computerprogrammen gibt, und die deshalb in der öffentlichen Diskussion noch nicht die notwendige Beachtung gefunden hat. Aber je weiter die Digitalisierung der Welt fortschreitet, desto wichtiger und drängender werden diese Fragen.
Auch Anfang der 1970er Jahre brauchten die Informatiker, die in Rechenzentren arbeiteten, ein Betriebssystem für ihre Maschinen.
In den AT&T Bell Laboratories (USA) wurde daher das Betriebssystem "Unix" entwickelt. Beteiligt waren u.a. Ken Thompson, Dennis Ritchie und Brian Kernighan.
Ihre Arbeitsumgebung sah so aus.
Die erste Version von Unix wurde 1973 fertiggestellt.
Um die Kommandozeilenbefehle von Unix programmieren zu können, entwickelte Dennis Ritchie die Programmiersprache C.
1991 war Linus Torvalds Informatikstudent an der Universität von Helsinki. Als Teenager in den 1980er Jahren hatte er den Heimcomputer VC-20 und später den Sinclair QL. Für diese etwas exotischen Geräte gab es nicht viel Software. Daher verbrachte er anders als die meisten anderen Gleichaltrigen seine Zeit nicht mit Computerspielen, sondern lernte, diese Geräte auf einer sehr grundlegenden Ebene zu programmieren, damit er seine eigenen Programme schreiben konnte.
Als Student kaufte er sich einen PC mit einem 386er-Prozessor (Intel 80386 - sehr weit verbreitet in der ersten Hälfte der 1990er Jahre). An der Universität fand eine Veranstaltung über Unix statt, die sich auf das Buch "The Design of the UNIX Operating System" (Maurice Bach, 1986) bezog.
So kam Linus Torvalds auf die Idee, ein unixartiges Betriebssystem für seinen 386er-PC zu schreiben.
Er gab seine Pläne in einer Newsgroup bekannt, erhielt Hilfe von Anderen und hatte schließlich Erfolg.
Linux ist also grundsätzlich ein freier Klon von Unix. Damals dachte niemand daran, daß es eines Tages das altehrwürdige, kommerzielle Unix verdrängen könnte.
Linux' Maskottchen ist ein Pinguin namens "Tux":
Unix war in den 1970er Jahren seiner Zeit weit voraus. Insbesondere war es von Anfang an ein Multitasking-Betriebssystem, das auf mehrere Benutzer ausgelegt war, und daher Benutzerrechte verwalten konnte.
Microsoft DOS (MS-DOS), erstmals 1981 veröffentlicht, unterstützte dagegen nur einen Task und einen Benutzer.
In Unix/Linux führt Multitasking dazu, daß jedes Programm in seiner eigenen, getrennten Umgebung abläuft. Programme können also abstürzen wie in jedem anderen Betriebssystem auch. Aber das zieht in Unix/Linux nicht den Rest des Systems mit sich. Der Rest des Systems ist normalerweise vom Absturz eines Programms nicht betroffen und bleibt also intakt. Deshalb ist Unix/Linux bekannt dafür, besonders stabil zu laufen.
Da Unix dafür ausgelegt war, daß mehrere Benutzer einen Computer über mehrere Terminal-Tastaturen benutzen sollten, sah es eine Benutzerverwaltung und Benutzerrechte vor. Und das tut auch Linux. Wenn man Linux bootet, gelangt man nach einer Weile zu einem Login-Bildschirm. Dort muß man den Benutzernamen und sein Passwort eingeben. Erst danach werden die eigenen Benutzereinstellungen geladen, und man kann das System benutzen.
Heutige Linux-Varianten bieten wahrscheinlich eine graphische Benutzeroberfläche, aber das ist noch nicht einmal notwendig: Man kann sich in ein Linux-System auch nur im Textmodus einloggen, der wie MS-DOS aussieht.
Auch heute noch brauchen insbesondere Server-Computer nicht unbedingt graphische Oberflächen.
Auch wenn einen der Boot-Prozess zu einer graphischen Oberfläche bringt, kann man dennoch auf andere virtuelle Konsolen im Textmodus wechseln, indem man eine der Tastenkombinationen von "Strg+Alt+F1" bis "Strg+Alt+F6" drückt..
Mit "Strg+Alt+F7" kommt man dann zur graphischen Oberfläche zurück.
Die Dateien, mit denen ein Benutzer arbeitet, sind in einem Verzeichnis namens "/home/benutzername" abgelegt. Das heißt, wenn es einen Benutzer mit dem Benutzernamen "john" gibt, dann befinden sich dessen Dateien unterhalb von "/home/john".
Dateien und Verzeichnisse gehören bestimmten Benutzern.
Zu jeder Datei und zu jedem Verzeichnis werden Benutzerrechte gespeichert. Dabei gibt es drei Arten von Rechten: Das Recht zu lesen (r für "read"), zu schreiben (w für "write") und auszuführen (x für "execute").
Wenn "john" eine Datei "hallo.txt" erzeugt, wird er Eigentümer dieser Datei und kann die Benutzerrechte, die andere daran haben, setzen, das heißt, er kann bestimmen, ob andere die Datei lesen, überschreiben oder ausführen dürfen.
Und dann gibt es noch den System-Administrator. Sein Benutzername ist immer "root". root darf alles im System tun. Z.B. kann er sogar ohne weiteres System-Dateien löschen, die notwendig wären, damit das System überhaupt läuft. root darf also auf jede erdenkliche Weise in das System eingreifen.
root darf auch auf alle Dateien aller Benutzer zugreifen, gleichgültig, welche Rechte die Benutzer gesetzt haben.
Und root kann auch die Benutzerrechte von Eigentümern von Dateien neu setzen, also wiederum bestimmen, ob die Eigentümer ihre eigenen Dateien lesen, überschreiben oder ausführen dürfen.
Wenn also "john" eine Datei gehört, kann "root" sie verändern, er kann sich auch selbst zum Eigentümer machen oder einen dritten Benutzer zum Eigentümer bestimmen, sagen wir "paul". Ebenso kann er z.B. "john" die Erlaubnis entziehen, seine eigene Datei zu lesen.
Benutzer können auch Mitglieder von Gruppen (groups) sein. Auch für Gruppen können wieder die drei Arten von Rechten gesetzt werden.
Insgesamt sehen, die Benutzerrechte, die zusammen mit einer Datei gespeichert werden, also so aus:
rwx (Eigentümer) rwx (Gruppe) rwx (Andere Benutzer)
Ein Beispiel: Angenommen, "john" erstellt die Datei "hallo.txt". Sie enthält vertraulichen Text. Er selbst möchte in der Lage sein, die Datei zu lesen und zu überschreiben, aber nicht, sie auszuführen, denn es ist ja eine Text-Datei. Gruppen und andere Benutzer sollen dagegen nichts mit der Textdatei machen dürfen. Also würde "john" für die Datei die Rechte folgendermaßen setzen: "rw- --- ---".
Auf Verzeichnisse kann nur zugegriffen werden, wenn das Recht "ausführen (x)" für sie gesetzt ist. "john" hat sein eigenes Heimatverzeichnis "/home/john", und "paul" hat sein eigenes Heimatverzeichnis "/home/paul". Wenn das "x"-Recht von "john"s Heimatverzeichnis nicht für Gruppen oder andere Benutzer gesetzt ist, und "paul" dennoch versucht, nach "/home/john" zu wechseln, wird er scheitern und eine Fehlermeldung darüber erhalten, daß er keine ausreichenden Rechte hat, um auf dieses Verzeichnis zuzugreifen.
Dieses System von Benutzerrechten trägt erheblich zur Sicherheit von Linux-Systemen bei.
Auch stärkt es die Sicherheit im Hinblick auf Viren. Viren sind unter Linux bislang kein so großes Problem, weil Windows deutlich weiter verbreitet ist als Linux, so daß die Virenprogrammierer mehr daran interessiert sind, Windows-Systeme anzugreifen.
Es ist auch durchaus möglich, ein Linux-System mit nur einem Benutzer zu betreiben. Dieser Benutzer muß dann auch zugleich der System-Administrator "root" sein. Aus Sicherheitsgründen sollte man in dem Fall jedoch auch noch ein Benutzerkonto für einen normalen Benutzer anlegen. Auf einem System mit nur einem Benutzer arbeitet man also gewöhnlich als normaler Benutzer. Nur wenn man Änderungen an den System-Dateien vornehmen muß, wird man für kurze Zeit "root". Dies geschieht, indem man in der Shell den Befehl "su" verwendet ("su" als Abkürzung für "superuser").
Unter Windows werden die Dateien auf der Festplatte unter "C:\" angezeigt.
Der eine oder andere mag sich daran erinnern, daß die Laufwerke "A:" und "B:" für Floppy-Disk-Laufwerke gedacht waren.
Der Dateipfad zu einer ausführbaren Datei unter Windows kann also z.B. so aussehen:
C:\Programme\MeinProgramm\meinprog.exe
Systemdateien findet man in dem Verzeichnis
C:\Windows
insbesondere in:
C:\Windows\System
Z.B. System-Bibliotheken ("Dynamic-link libraries", Suffix ".dll") sind hier gespeichert.
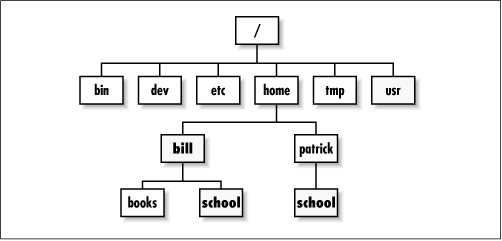
Unter Linux ist das alles ganz anders. Es gibt stattdessen einen Verzeichnisbaum.
Das Trennzeichen für die Verzeichnisnamen ist der Schrägstrich "/", nicht der Backslash "\" (wie unter Windows).
Wie oben bereits gesagt, befinden sich die Dateien eines Benutzers in dessen Heimatverzeichnis, so sind "john"s Dateien in "/home/john".
Nur der Benutzer "root" hat Schreibzugriff auf die meisten Systemdateien.
Die Wurzel des Linux-Verzeichnisbaums ist bei "/". Verwendet man einen Dateimanager wie "dolphin", "nautilus" oder "PCManFM" und schaut sich "/" an, sieht man darin folgende Verzeichnisse:
bin boot dev etc home lib media opt proc root tmp usr var windows
Diese Verzeichnisse haben die folgenden Inhalte, bzw. Bedeutungen:
Zu beachten ist, daß Linux anders als Windows stets Groß- und Kleinschreibung beachtet. Das bedeutet, "/home/john" ist etwas völlig anderes als "/home/John".
Beide Verzeichnisse würden existieren, wären aber vollständig verschieden.
Der Linux-Verzeichnisbaum bezieht sich also nicht auf ein bestimmtes Laufwerk (wie unter Windows "C:\"). Stattdessen sind die Dateien, von denen aus Linux bootet, über den ganzen Verzeichnisbaum verteilt. Die meisten davon sind Systemdateien. Wenn Dateien einer externen Festplatte oder eines USB-Sticks benötigt werden, findet man sie unter "/media" (oder früher: "/mnt"), wo das Laufwerk oder der Stick eingehängt werden.
Einfache Benutzer bleiben normalerweise in ihrem Heimverzeichnis ("/home/john" für den Benutzer "john"). Dort können sie eine nahezu unbegrenzte Anzahl von Unterverzeichnissen erstellen.
Dennoch können Benutzer auch aus ihrem Heimverzeichnis heraus Programme ausführen, die in den Verzeichnissen "/usr/bin" oder "/usr/local/bin" gespeichert sind.
Wegen der $PATH-Variable müssen sie nicht erst in diese System-Verzeichnisse wechseln, um diese Programme auszuführen.
Sie können in ihrem Heimverzeichnis bleiben, und das System findet die Programme für sie.
Wenn man den Linux-Verzeichnisbaum zum ersten Mal sieht, ist das für einen sicherlich ein ungewohnter Anblick.
"Was um alles in der Welt ist das denn?", wird man sich vielleicht fragen.
Aber die meisten Verzeichnisse enthalten Dateien eines Typs, den Windows gewöhnlich vor Benutzern in dem Verzeichnis "C:\Windows\System" verbirgt. Wann muß man schon in dieses Verzeichnis hineinschauen?
Außerdem: Wenn man weiterhin Linux benutzt, gewöhnt man sich an den Verzeichnisbaum in vielleicht ein paar Tagen oder Wochen.
Es gibt ihn aber schon seit Jahrzehnten. Wahrscheinlich wird er auch noch weitere Jahrzehnte so bleiben. Ich arbeite mit ihm seit nun mehr als 10 Jahren.
Das Wissen über den Linux-Verzeichnisbaum ist also etwas, das man wirklich für's Leben lernt. Vielleicht wird man es noch seinen Enkelkindern beibringen. Es lohnt sich also, sich damit vertraut zu machen.
Um ein Programm in Windows zu starten, klickt man doppelt auf sein Desktop-Icon. Oder man klickt auf das Start-Menü, sucht das gewünschte Programm heraus, und klickt darauf. Icons und Menüeinträge enthalten Verknüpfungen zu den ausführbaren Dateien in den Verzeichnissen auf der Festplatte.
Dies kann recht ähnlich unter Linux sein, vorausgesetzt, Icons und Menüs sind richtig installiert. Natürlich sind die Programmdateien in den Verzeichnissen, aber nicht jedes Programm installiert Desktop-Icons und Menüeinträge korrekt. Deshalb arbeitet man häufiger mit den echten Verzeichnissen auf der Festplatte oder startet Programme, indem man ein Terminal öffnet und den Namen des Programms eintippt. Unter Linux gibt es mehrere Terminal-Programme, z.B. "xterm", "rxvt" oder "konsole". Sie sind vergleichbar mit der "MS-DOS-Eingabeaufforderung" unter Windows (nur besser).
Wenn man ein Terminal-Programm unter Linux startet, öffnet sich ein Fenster mit einer Eingabezeile, in die man Systembefehle eingeben kann.
(Das Erscheinungsbild dieses Fensters, also z.B. die Größe der Fonts innerhalb des Fensters, läßt sich einstellen.)
MS-DOS hatte seine eigene Shell-Sprache mit Befehlen wie "dir" oder "copy".
Obwohl die Befehle unter Linux etwas Ähnliches tun, unterscheidet sich die Sprache jedoch davon, weil sie aus der Unix-Tradition stammt. In einem Terminal läuft also eine Shell, gewöhnlich die Shell "bash" ("GNU Bourne-Again Shell").
Hier sind einige grundlegende Befehle in bash:
Zum Löschen von Dateien: Dateien werden mit dem Befehl "rm" ("remove") gelöscht. Zusammen mit der Option "-r" wird dieser Befehl auch zum Löschen von Verzeichnissen verwendet. Allerdings gibt es hier keinen Sicherheitsmechanismus (wie z.B. einen "Papierkorb"). Gelöschte Daten sind also grundsätzlich für immer verloren. Bildlich gesprochen übergibt einem Linux an dieser Stelle eine geladene Pistole und schützt einen nicht davor, sich damit in den Fuß zu schießen. Linux geht also von einem erwachsenen Benutzer aus, der für seine eigenen Handlungen verantwortlich ist. Beim Löschen von Dateien muß man also selbst aufpassen, daß keine wichtigen Daten verlorengehen.
Shell-Befehle haben zahlreiche Optionen. Man kann Informationen über diese erhalten, indem man "man " eingibt, und dann den Namen des Befehls ("man" steht für "Manual"), wie z.B. "man ls".
Außerdem können eine Reihe von Symbolen in der Shell benutzt werden:
Der Befehl
mv ./meineDatei.txt ~
bedeutet also: "Bewege die Datei 'meineDatei.txt' vom aktuellen Verzeichnis in mein Heimatverzeichnis."
Eine Funktion der bash macht das Arbeiten besonders angenehm: Sie heißt "TAB-Ergänzung" ("TAB-completion"): Wenn man nur ein paar Buchstaben des Namens eines Befehls oder einer Datei eingibt, auf die man sich bezieht, und dann TAB (die Tabulator-Taste) drückt, vervollständigt bash automatisch den restlichen Teil des Befehls- oder Dateinamens. Man muß also Dateinamen nicht ganz eingeben. Meist gibt man nur ein paar Buchstaben ein, drückt dann die Tabulator-Taste und hat schon, was man will. Wenn die Buchstaben mehrere Möglichkeiten zulassen, zeigt bash diese an, wenn man TAB zweimal hintereinander drückt.
bash kann auf verschiedene Weise konfiguriert werden.
Wenn man z.B. unterhalb seines Heimatverzeichnisses ein Standard-Arbeitsverzeichnis eingerichtet hat, kann man die Shell so konfigurieren, daß sie jedesmal direkt in diesem Verzeichnis startet.
Desktopumgebungen lassen einen Tastaturkürzel definieren, um ein Terminal oder andere Programme zu öffnen. Man kann dann also dieses Kürzel drücken und ist sofort in bash in dem Standard-Arbeitsverzeichnis. Das ist sehr schnell und sehr nützlich. Aus diesem Grund wird unter Linux immer noch häufig die Kommandozeile benutzt.
Die Sprache von bash ist auch eine Programmiersprache. Bash-Skripte werden unter anderem häufig als Installationsroutinen verwendet. Sie spielen auch eine wichtige Rolle im Boot-Prozess von Linux.
Im Jahr 2016 hat auch Microsoft erkannt, daß bash sehr leistungsfähig ist und es in Windows 10 integriert.
Linux-Programme folgen häufig einem Designgrundsatz, der aus der Unix-Tradition stammt. Danach sollte ein Programm nur eine Aufgabe erledigen, diese aber gut. Um komplexere Aufgaben zu erfüllen, sollte es mit anderen Programmen zusammenarbeiten.
Dieses Prinzip führt zu einer Vielzahl von sehr kleinen Programmen, deren Funktion der Benutzer zunächst vielleicht nicht sofort versteht.
Das Programm "k3b" verwirklicht den Grundsatz beispielhaft. Es bietet eine graphische Oberfläche, um CDs und DVDs zu brennen. Im Hintergrund arbeitet k3b mit mehreren Kommandozeilenprogrammen zusammen, die einzelne Aufgaben erfüllen. Nur um ein Beispiel zu geben, dies sind in diesem Fall etwa (muß man sich nicht merken):
"mkisofs" erstellt etwa ein Dateisystem und also ".iso"-Dateien, "normalize" normalisiert Lautstärken in Audio-Dateien.
Es arbeiten also viel kleine Programme zusammen, um insgesamt das Brennen von CDs und DVDs zu ermöglichen.
Der Nutzer braucht mit diesen kleinen Programmen nicht in Berührung zu kommen, er kann einfach das graphische Frontend, hier "k3b", verwenden. Es kann aber auch sein, daß er in der Shell auf solche Einzelprogramme stößt, und dann zunächst nicht weiß, wofür diese gut sein sollen. Natürlich hindert ihn aber auch niemand, die Einzelprogramme zu benutzen, wenn er weiß, wie man das macht (bei "normalize" z.B. ist es ja nicht schwierig).
Das Verwenden von Einzelprogrammen hat den Vorteil, daß sie von mehreren größeren Anwendungen benutzt werden können, wobei sie gegebenenfalls in verschiedener Weise kombiniert werden können. So kann nicht nur "k3b", sondern etwa auch ein Audio-Bearbeitungsprogramm ein kleines Einzelprogrammen wie "normalize" gebrauchen. Die Einzelprogramme sind also in gewisser Weise wie Module, die ein größeres Programm einbinden kann, ohne daß der Code für die Aufgabe, die das Programm erfüllt, noch einmal geschrieben werden muß.
Unter Windows hat man dagegen eine große Anwendung, die viele Aufgaben auf einmal zu erfüllen versucht.
Einige Linux-Programme verlassen die Unix-Tradition, und gehen eher zur integrierenden Methode von Windows-Anwendungen über. Firefox und Thunderbird verhalten sich in der Hinsicht im Grunde wie Windows-Anwendungen, das Email-Programm "kmail" ebenfalls.
Dennoch sollte man von dem Designgrundsatz aus der Unix-Tradition "Mache nur eine Sache und mache sie gut" mal gehört haben, um zu verstehen, warum man auf einem Linux-System so viele kleine merkwürdige Programme vorfindet, bei denen man zunächst gar nicht weiß, wozu sie gut sind.
Wenn man Windows kauft, oder wenn man einen Computer kauft, auf dem bereits Windows installiert ist, bekommt man nur Windows, also das Betriebssystem.
Wenn man Anwendungen wie Spiele oder z.B. Microsoft Office benutzen will, muß man diese gesondert kaufen.
Bei Freier Software ist es dagegen nicht nötig, Betriebssystem und sonstige Anwendungen zu trennen. Daher erhält man mit Linux normalerweise sowohl das Betriebssystem also auch eine sehr große Anzahl von Anwendungen (wie z.B. LibreOffice).
Es wäre für einen durchschnittlichen Benutzer eine zu umfangreiche und schwierige Aufgabe, den Linux-Kernel und die GNU Utilities herunterzuladen und daraus sein eigenes Linux-System zusammenzustellen.
Es wären zu viele Konfigurationseinstellungen vorzunehmen.
Deshalb gibt es Unternehmen und Projekte, die große Software-Sammlungen zusammenstellen, die ein fertig konfiguriertes GNU/Linux Betriebssystem nebst Anwendungen enthalten. Eine solche Software-Sammlung nennt man "Linux-Distribution".
Einige Linux-Distributionen werden für Geld auf einer DVD in einer Verpackung und mit einer Broschüre verkauft. Die meisten Distributionen können kostenlos im Internet heruntergeladen werden. Man kann entweder einzelne Dateien der Distribution herunterladen oder eine ".iso"-Datei der ganzen Distribution, aus der man dann selbst eine DVD brennen muß.
Weitverbreitete Distributionen sind zum Beispiel:
Einige davon werden von Linux-Unternehmen erstellt (wie "Red Hat" oder "SuSE"). Oft gibt es dann eine kostenlose "Open" Version und eine kommerzielle "Enterprise"-Version. Diese Unternehmen erzielen den größten Teil ihrer Einnahmen mit Support-Dienstleistungen, die sie für andere Unternehmen erbringen, die z.B. Linux auf ihren Servern verwenden.
Es gibt auch spezialisierte, minimalistische Distributionen, die nur eine kleine Auswahl von Anwendungen enthalten (wie zum Beispiel "Arch Linux").
Und es gibt sehr kleine Distributionen (von einer Größe von z.B. nur etwa 250 MB), die zwar installiert werden können, aber auch nur von einer Boot-CD oder von einem USB-Stick laufen (wie "Puppy Linux" zum Beispiel). Bei der geringen Größe können moderne Computer die ganze Distribution in den Arbeitsspeicher laden. Tatsächlich kann man Puppy Linux recht gut für allgemeine Zwecke verwenden, aber oft wird diese Art von Distribution als Recovery-System, also für Wiederherstellungsarbeiten an einem defekten Hauptsystem, verwendet.
Da die Distributionen in gewisser Weise die System-Konfiguration bestimmen, enthalten die meisten Distributionen ein eigenes Programm für Systemeinstellungen (unter Windows gehört so ein Programm zum Betriebssystem und wird unter "Einstellungen/Systemsteuerung" aufgerufen).
Einem Anfänger würde ich raten, mit einer der oben genannten, größeren Distributionen zu beginnen. Das hängt auch davon ab, wie gut eine Distribution die eigene Hardware erkennt. Ich selbst bin bisher meistens mit openSUSE am besten zurechtgekommen. Diese Distribution benutze ich im Moment.
Die meisten aktuellen Linux-Distributionen enthalten auch Software, die nicht den Anforderungen an "Freie Software" entspricht.
openSUSE enthält auch Pakete von proprietärer Software, trennt diese aber von den Paketen mit Freier Software. Auf diese Weise hat man die Wahl, welche Art von Software man installieren und benutzen will.
Die "Free Software Foundation" hat eine Liste mit Distributionen erstellt, die nur Freie Software enthalten.
Außerdem gibt es eine Liste dazu, wie die größeren Distributionen das Thema "Freie Software" behandeln.
Bei Windows gibt es die "Systemsteuerung". Dort kann man seine Hardware konfigurieren und die Software-Installationen und Systemeinstellungen vornehmen.
In der "Registry", der Windows-Registrierungsdatenbank, sind fortgeschrittene Systemeinstellungen gespeichert. Die Registry kann mit dem Programm "regedit.exe" aus dem Verzeichnis "C:\Windows" bearbeitet werden.
In den meisten Linux-Distributionen gibt es ein Programm, das etwas Ähnliches tut wie die Windows-Systemsteuerung. Das entsprechende Programm von openSUSE heißt "YaST2" oder "yast2" ("Yet another Setup-Tool", Version 2). Hier ist ein Bildschirmfoto davon:
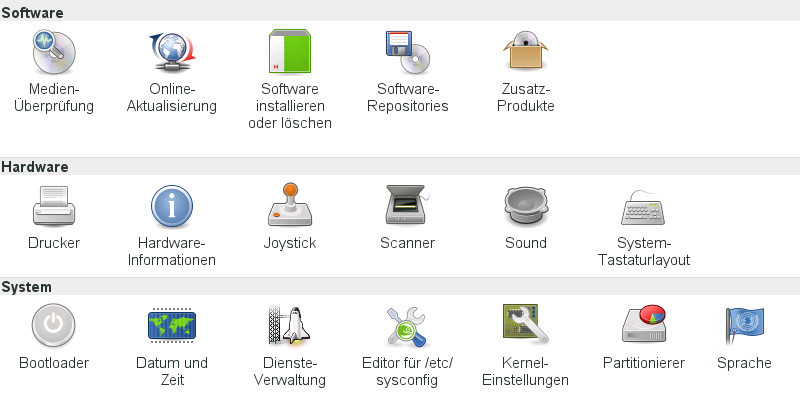
Tatsächlich werden die Einstellungen, die dort vorgenommen werden können, in einigen hundert Konfigurations-Textdateien im Verzeichnisbaum, insbesondere in "/etc", gespeichert.
YaST2 ist also ein graphisches Front-End, um bequem und relativ sicher Änderungen an diesen Konfigurationsdateien vorzunehmen.
In Linux gibt es also keine Registrierungsdatenbank wie in Windows. Stattdessen ist die gesamte Systemkonfiguration in diesen Nur-Text-Dateien im Verzeichnisbaum gespeichert. In den meisten Fällen muß man "root" sein, um sie bearbeiten zu können. Aber wenn man "root" ist, hindert einen niemand daran, diese Dateien und damit die Systemkonfiguration zu beschädigen.
Die meisten Programme ermöglichen es, daß jeder Benutzer seine eigene Programmkonfiguration hat. Zu diesem Zweck schreiben sie Konfigurationsdateien in das Heimatverzeichnis des Benutzers. Diese Dateien haben gewöhnlich den Status "versteckt". Dieser Status kann einfach dadurch hergestellt werden, daß man einen einzelnen Punkt vor den Dateinamen setzt. Die Konfigurationsdatei im Heimatverzeichnis des Benutzers für den Editor vim heißt z.B. ".vimrc".
Windows-Software enthält normalerweise ein Installationsprogram "setup.exe". Die Software wird in Verzeichnisse wie "C:\Programme" installiert, DLL-Bibliotheken werden dem Verzeichnis "C:\Windows\System" hinzugefügt, und Änderungen an der Windows-Registry werden vorgenommen.
Über die Systemsteuerung kann man Software wieder deinstallieren. Aber oft bleiben Programmüberreste im System, insbesondere in der Registry.
Nach einer gewissen Anzahl von Installationen und Deinstallationen führte dies meist dazu, daß Windows langsam wurde.
Linux-Software erhält man dagegen in sogenannten "Paketen". Diese können ".rpm" heißen (Redhat Package Manager) oder ".deb" (Debian Package). Da OpenSUSE rpm verwendet, kenne ich das am besten.
Während der Systeminstallation wird gewöhnlich eine gute Auswahl von mehrern hundert oder tausend rpm-Paketen installiert.
rpm-Dateien enthalten die Dateien, die installiert werden sollen, dann Beschreibungen der Pakete und der Dateien sowie Informationen darüber, wo diese Dateien installiert werden sollen.
YaST2 kennt die Pakete, die zur Distribution gehören. Es kann verwendet werden, um auch nach der Systeminstallation welche davon nachzuinstallieren.
YaST2 bietet eine graphische Oberfläche, auf der man einfach anklicken kann, welche Pakete man installieren oder deinstallieren möchte.
Wenn ein Paket installiert wird, wird seine Beschreibung in einer speziellen Datenbank auf dem System gespeichert.
Auch Bibliotheken sind in Paketen abgelegt. Da Programme oft von Bibliotheken abhängig sind, bestehen oft Abhängigkeiten zwischen Programmpaketen und Bibliothekpaketen.
Die Informationen über diese Abhängigkeiten sind auch in den rpm-Paketen gespeichert. Daher kennt YaST2 auch diese Abhängigkeiten.
Wenn man also YaST2 auffordert, das Audio-Programm "audacity" zu installieren, wird es auch die benötigten Bibliotheken des Alsa-Soundsystems mitinstallieren, sofern diese nicht schon installiert sind.
Soweit ich weiß, installiert und deinstalliert das rpm-System sauber, so daß keine Programmüberreste im System verbleiben. Deshalb werden Linux-Systems auch nach Jahren in Betrieb nicht langsam.
Noch etwas mehr Details: Die meiste Software für Linux ist in C oder C++ geschrieben. Entwickler schreiben also Source-Code in diesen Sprachen.
Auf ihren Projektwebseiten stellen sie gewöhnlich den Source-Code in einer Datei mit dem Suffix ".tar.gz" zur Verfügung.
Dabei handelt es sich um eine Archivdatei, ähnlich wie ".zip" unter Windows. "zip" gibt es auch unter Linux, aber traditionell wird ".tar.gz" verwendet, um Dateien und Verzeichnisse in einer Datei zu archivieren (heute auch häufiger ".tar.bz2").
Um eine Datei "meineDatei.tar.gz" zu extrahieren, würde man in der Shell schreiben: "tar -xzvf meineDatei.tar.gz".
Für eine "tar.bz2"-Datei "meineDatei.tar.bz2": "tar -xjvf meineDatei.tar.bz2".
Der ausgepackte Source-Code müßte erst für eine bestimmte Plattform kompiliert werden. Heute gibt es zum Beispiel 32 Bit- und 64 Bit-Systeme.
Beim Kompilieren von Software kann es oft Probleme geben. Möglicherweise hat sich eine Bibliothek, von der ein Programm abhängig ist, verändert, seit der Source-Code des Programms geschrieben wurde. Oder der Source-Code enthält schlicht Fehler.
Aber die Leute, die die Linux-Distributionen zusammenstellen, schaffen es, den Source-Code für die Plattformen zu kompilieren, die ihre Distribution unterstützt.
Daher gibt es ausführbare Dateien, die auf diesen Plattformen laufen. Diese Dateien werden dann in rpm-Pakete gepackt.
Wenn man also ein bestimmtes Programm sucht, sollte man immer überprüfen, ob die eigene Distribution ein rpm-Paket davon zur Verfügung stellt. Wenn sie es tut, sollte man das Programm von dort installieren.
Der Name einer rpm-Datei enthält die Versionsnummer des Programms sowie die Bezeichnung der Plattform, für die es kompiliert wurde. Zum Beispiel kann das rpm-Paket von alsa ("Advanced Linux Sound Architecture", alsa ist das traditionelle Linux-Soundsystem) etwa so aussehen:
alsa-1.0.27.2-3.2.1.i586.rpm
Also erst der Name, dann eine Versionsnummer, dann "i586" für den 32 Bit Intel-Pentium-Prozessor als Minimum, schließlich der Suffix ".rpm". Die Version desselben Source-Codes für ein 64 Bit-System sähe z.B. so aus:
alsa-1.0.27.2-3.2.1.x86_64.rpm
Wieder der Name, dieselbe Versionsnummer, dann"x86_64", also 64 Bit, schließlich wieder der Suffix ".rpm".
Wenn man bei seiner Distribution bleibt, werden automatisch die richtigen Pakete installiert. Man sollte sich nur darüber klar sein, daß es verschiedene Versionen derselben Software für verschiedene Plattformen geben kann. Manchmal muß man daher das richtige Paket für sein System auswählen.
Wenn man unter Windows ein Programm installiert, muß man danach den Computer häufig neu starten. Unter Linux braucht man das mit dem rpm-System nicht. Dafür muß man häufiger als "root" Änderungen an den Systemeinstellungen vornehmen. Daher kam der Spruch: "Windows - reboot, Linux - be root".
Wenn man Windows startet, wird nach einer Weile der Desktop angezeigt. Darauf sind vielleicht ein paar Icons oder Kacheln und ein Start-Knopf mit einem Menü.
In GNU/Linux wird die grafische Oberfläche dagegen von zwei verschiedenen Programmen gemeinsam erzeugt, von einem Server und einem Client.
Der Server heißt "X-Server" oder "X Window System", das Projekt heißt "X.org" (es hat sogar tatsächlich eine Webseite "http://www.x.org").
Der Client verbindet sich mit dem X-server. Er heißt "Window-Manager".
Es gibt mehrere verschiedene Window-Manager. Hier sind die Namen von einigen von ihnen. Einige sind Teil größerer Desktopumgebungen ("desktop environments"):
KDE and Gnome sind die größten Desktopumgebungen. Die übrigen sind kleinere Window-Manager, die auch weniger Ressourcen in Anspruch nehmen.
Ich bin mit LXDE im Moment ganz zufrieden.
Die graphische Oberfläche eines Linux-Systems ist also nicht festgelegt.
Es gibt viele Möglichkeiten, wie sie aussehen kann.
Wahrscheinlich ist deshalb das Maskottchen des Unternehmens SuSE ein Chamäleon.
Doch obwohl der Desktop unterschiedlich aussehen kann, gelten doch stets die Prinzipien von Linux, also die des Verzeichnisbaums, der Benutzerverwaltung mit dem System-Administrator "root", der Konfigurationsdateien und der Shell.
Deshalb ist es sinnvoll, sich mit diesen Dingen etwas auszukennen.
Man kann auch mehrere Window-Manager auf seinem Linux-System installieren. Man kann dann einen davon benutzen, z.B. LXDE, aber man kann dann auch von LXDE aus Anwendungen starten, die eigentlich für andere Umgebungen geschrieben wurden, etwa für KDE oder Gnome.
Bei der Programmierung von Fensteranwendungen ("Grafischen Benutzeroberflächen", "Graphical User Interfaces", GUI), werden sogenannte "Widgets" verwendet. Das Wort "Widget" ist eine Abkürzung von "window gadget" und bedeutet soviel wie "Element eines Anwendungsfensters". Widgets können z.B. Knöpfe, Eingabefelder, Schieberegler oder Auswahlkästchen sein.
Dabei schreiben Entwickler Code für eine bestimmte Softwareschicht, die man "Toolkit" nennt. Diese bewirkt die richtige Darstellung der Widgets.
Windows enthält ein eigenes Toolkit, das Anwendungen das Aussehen von Windows-Fenstern gibt.
Natürlich gibt es unter Linux wiederum mehrere Toolkits.
Deshalb sehen auch die Fenster der Anwendungen ein wenig anders aus als die unter Windows.
KDE ist auf dem Toolkit "Qt" aufgebaut, Gnome auf dem Toolkit "GTK".
Dann gibt es noch ein kleineres Toolkit namens "Tk", das für kleine bis mittelgroße Anwendungen geeignet ist.
Tk-Anwendungen sind nicht gerade schön, aber sie funktionieren. Die Vorteile von Tk sind seine geringe Größe, und daß es relativ leicht zu lernen ist, damit Benutzeroberflächen zu schreiben.
Deshalb wird es oft in Verbindung mit Skriptsprachen wie Perl (Perl/Tk) oder Python (Tkinter) verwendet. Ursprünglich war Tk das Toolkit für die Skriptsprache Tcl (Tcl/Tk).
Hier sind einige Anwendungen von Projekten Freier Software.
Die meisten davon bieten auch Versionen für Windows an. Es ist also auch möglich, Freie Software auf einem proprietären Betriebssytem zu verwenden:
| LibreOffice | Office-Paket (ein abespaltener Entwicklungszweig von OpenOffice). |
| Firefox | Internetbrowser. |
| Thunderbird, kmail | Email-Programme. |
| FileZilla | ftp-Client. |
| Gimp | Grafikprogramm: GNU Image Manipulation Program. |
| Audacity | Programm zur Soundbearbeitung. |
| MPlayer | Leistungsfähiges Programm zum Abspielen und Umwandeln von Videos and Musik. |
| Dolphin | Dateimanager im Stile des Windows Explorers (wahrscheinlich nur für Linux). |
| Midnight Commander | Graphischer Dateimanager für das Linux-Terminal im Stil des Norton Commanders (nur Linux). |
Man muß aufpassen, daß man derartige Programme von vertrauenswürdigen Internet-Seiten herunterlädt, auf denen man sie kostenlos und ohne Viren bekommt.
Unter Linux sind diese Programme in der Regel Teil der Distribution, und werden also über das Programmpaketsystem der Distribution installiert.
Unter Windows gibt man am besten den Namen des Programms bei Wikipedia ein, und sucht dort nach den ursprünglichen Webseiten der Projekte.
Oder man sucht in den Download-Bereichen von Webseiten bekannter Computerzeitschriften wie z.B. "Chip".
Wie oben erläutert, beruht die Entwicklung Freier Software auf dem Prinzip, daß viele Leute (real oder virtuell) zusammenkommen und Code schreiben. Aber Spiele bestehen nicht nur aus Code. Zusätzlich braucht man eine gute Idee für ein Spiel oder gegebenenfalls eine Spielhandlung. Und dann braucht man insbesondere künstlerische Werke wie Graphiken und Sound. Es scheint so, daß die Idee, daß viele Leute zusammenarbeiten, nicht besonders gut funktioniert, wenn es um Kunst geht. Kunstwerke werden oft von einer einzigen, in besonderer Weise begabten Person, dem Künstler, geschaffen. Man denke an Tolkiens "Herr der Ringe", die Gemälde von Picasso oder die Musik von Beethoven.
Vielleicht ist das der Grund, warum es deutliche weniger Spiele für Linux gibt als für Windows. Das Konzept eines einzigen Wirtschaftsunternehmens, das Künstler beschäftigen und auch für längere Zeit bezahlen kann, scheint für die Entwicklung von Spielen besser zu funktionieren.
Es gibt eine ganze Reihe von Spielen für Linux, aber nicht viele von diesen hypermodernen 3D-Blockbuster-Shootern, die man möglicherweise von Windows kennt. Stattdessen gibt es kleinere Karten oder Brettspiele wie:
Dann gibt es einige 2D-Spiele wie:
Heutzutage gibt es auch Spiele, die im Browser ablaufen.
Dann gibt es noch einige alte kommerzielle Spiele, die im Laufe der Jahre Freeware oder sogar Open Source geworden sind. "Beneath a Steel Sky", ein Point-and-Click-Adventure von 1994, wäre eines davon.
Oder der 3D-Online-Shooter "Wolfenstein: Enemy Territory", der immer noch recht beliebt ist.
"ScummVM" macht es möglich, die großen alten LucasArts Point-and-Click-Adventure wie "Monkey Island" 1 und 2, "Indiana Jones and the Fate of Atlantis" oder "The Dig" zu spielen. Wenn man diese Spiele bereits hat.
Auf ScummVMs Seite kann man aber auch einige Spiele dieser Art kostenlos herunterladen.
Dann gibt es noch eine Reihe von recht guten Emulatoren von anderen, älteren Computern. Es gibt Emulatoren des Sinclair ZX Spectrum ("Fuse"), des Atari 800 XL ("atari++"), des Commodore Amiga ("uae"), des Atari ST ("steem"), des Commodore C64 ("Vice") und sogar von alten Arcade-Spielgeräten ("Mame"). Für diese alten Systeme gab es eine Menge Spiele. Es könnte sein, daß einige davon inzwischen kostenlos sind.
Man kann also unter Linux viele Jahre lang Spaß mit Spielen haben. Obwohl man wahrscheinlich nicht die neuesten, größten Spiele für Playstation, X-Box oder Windows spielen kann. Aber muß man das wirklich?
In den meisten Fällen ist es nicht nötig, Windows-Software auf Linux laufen zu lassen. Die meisten Aufgaben lassen sich mit nativen Linux-Programmen erfüllen.
Sollte es tatsächlich mal eine Anwendung geben, die man unbedingt braucht, die aber nur auf Windows läuft, dann wäre mein Rat, sie auch unter Windows laufen zu lassen.
Nichtsdestotrotz gibt es ein Linux-Programm namens "Wine", mit dem man bis zu einem gewissen Grade Windows-Software auf Linux laufen lassen kann. Das ist aber sehr experimentell. Es kann funktionieren, oder auch nicht. Um ehrlich zu sein, sind meine Erfahrungen mit Wine nicht sehr gut. Manchmal war ich ganz überrascht, was damit möglich ist, aber in den meisten Fällen konnte es Windows nicht einfach ersetzen. Vielleicht wäre das auch ein bißchen viel verlangt.
Ein anderer Ansatz wäre "Virtualisation", also auch die Hardware eines anderen PCs innerhalb von Linux in einer "virtuellen Maschine" zu emulieren. Das Programm "VirtualBox" macht das bis zu einem gewissen Grade.
Aber wie ich schon sagte, am besten ist es, natives Windows zu verwenden, um Windows-Programme zu benutzen. Doch wenn man Linux benutzt, und sich ein bißchen damit auskennt, braucht man das meistens nicht.
bash (die Shell) ist ein Kommandozeileninterpreter (CLI). Man kann bash als Programmersprache verwenden, es ist also eine interpretierte Sprache. Ein Interpreter liest Code als Text ein und führt diesen Zeile für Zeile aus. Demgegenüber muß in C/C++ der Source-Code kompiliert werden, so daß ausführbare Dateien erzeugt werden.
1986 arbeitete ein Programmierer und Linguist names Larry Wall bei einer Einrichtung irgendwo in den USA. Er mußte große Mengen Text automatisiert verarbeiten, und war damit unzufrieden, welche Art von Code er dafür in C schreiben mußte.
Um sich die Arbeit zu erleichtern, entwickelte er eine interprierte Programmersprache namens "Perl", bei der er Elemente von C und bash miteinander vermischte (und von einigen der seltsamen Befehle, die man in Unix zur Datenverarbeitung verwendet, nämlich "awk", "grep" und "sed").
Er veröffentlichte seine Sprache unter einer freien Lizenz, so daß der Perl-Interpreter heute auf den meisten Linux-Systemen zu finden ist.
Es gibt eine zentrale Datenbank im Internet für Perl-Module für nahezu jede Programmieraufgabe namens "CPAN".
Im allgemeinen läuft Perl-Code langsamer als vergleichbarer C-Code, aber er ist für den Programmierer wesentlich einfacher zu schreiben. Durch die große Menge an verfügbaren Modulen kann man manchmal erstaunliche Dinge mit nur ein paar Zeilen Code programmieren.
1991 entwickelte ein anderer Programmierer namens Guido van Rossum eine ähnliche interpretierte Programmersprache namens "Python". In dieser Sprache ist es noch einfacher, Coder zu schreiben, und der Code sieht deutlich sauberer aus. Dadurch ist es einfacher, ihn auch noch einige Monate oder Jahre später zu lesen und zu warten.
Außerdem ist der Programmierstil der "Objektorientierten Programmierung" in Python sauberer implementiert.
Auch der Python-Interpreter ist Freie Software, und ist auf den meisten Linux-Systemen zu finden.
Oft wird Python Version 2.7 verwendet. Leider wurden in Version 3 einige Dinge eingeführt, die als Schritte in die falsche Richtung angesehen wurden.
Wenn man sich also eines Tages auch mit Programmierung beschäftigen wollte, wären Perl oder Python für den Einstieg eine gute Wahl. Traditionell begannen viele Linux-Benutzer erst mit bash, gingen dann zu Perl über und lernten schließlich auch C.
Kostenlose Distributionen von Perl und Python sind auch für Windows verfügbar.
Richard Stallmans Ziel ist es, mit Hilfe von Freier Software dafür zu sorgen, daß der Benutzer die Kontrolle über sein Computersystem behält.
Das ist die Ausnahme. Der Rest der Welt versucht, selbst die Kontrolle über die Computersysteme oder zumindest über die persönlichen Daten der Benutzer zu erlangen.
Vor diesem Hintergrund überrascht es nicht, daß versucht wird, in negativer Weise auf Linux-Systeme Einfluß zu nehmen.
Darüber, ob Dienste wie die NSA versucht haben, eine Hintertür ("Backdoor") in den Linux-Kernel einzubauen, kann nur spekuliert werden. Jedoch würden die Entwickler früher oder später Schadcode entdecken und entfernen, da der Source-Code eben frei zugänglich ist und von vielen unabhängigen Personen gelesen wird und verändert werden kann.
Ein neues System für den Linux-Startprozeß namens "systemd", das insbesondere auf den Programmierer Lennart Poettering zurückgeht, greift unnötig tief in das System ein. Es speichert log-Dateien ohne triftigen Grund im Binärformat statt im Nur-Text-Format, so daß sie nicht mehr ohne weiteres vom Benutzer gelesen werden können.
Zwar bietet systemd auch einige Vorteile, aber es hat zu großer Unruhe in der Linux-Community geführt.
Auch beim Einbinden von Geräten wird dem Benutzer zunehmend die Kontrolle entzogen. Während er früher über die Datei "/etc/fstab" eindeutig festlegen konnte, welche Geräte eingebunden wurden, werden nun durch eine Dienst namens "udev" Gerätebezeichnungen erst dann dynamisch vergeben, wenn das Gerät eingesteckt wird. Wenn dies automatisch gelingt, mag es praktisch sein, doch wenn der Benutzer eingreifen muß, wird er mit einem schwer zu durchschauenden System von "Policies" und dynamisch erzeugten Gerätedateien mit kryptischen Dateinamen konfrontiert, die schon wieder verschwinden, sobald das Gerät wieder entfernt wird. So wird es für den Benutzer schwierig, seine Konfigurationsdateien auf sein Gerät hin anzupassen.
Ein mir verdächtiges Projekt ist auch Nepomuk. "Metadaten aus verschiedenen Desktop-Anwendungen" sollen "gesammelt und vernetzt" werden. Wozu? Bei Wikipedia (s.o.) heißt es:
Nepomuk wurde durch das NEPOMUK-Projekt entwickelt. Die Kosten betrugen 17 Mio. Euro, davon wurden 11,5 Mio. durch die Europäische Union finanziert.
Warum sollte die Entwicklung eines solchen Programms für den Desktop derartige Summen verschlingen? Und warum hat die EU ein so starkes Interesse an so einem Metadatenprogramm, daß sie dafür diese Mittel aufbringt? Und wer hat die restlichen 5,5 Mio. EUR bezahlt? Wem nützt das?
Ein weiteres Programm in dieser Richtung ist Akonadi. Es verwaltet zentral das Adreßbuch und weitere persönliche Daten.
Bei einer Installation kam mein System im ausgelieferten Zustand völlig zum Erliegen. Erst nach der Deinstallation von Nepomuk und Akonadi lief es mit normaler Geschwindigkeit.
Als weitere KDE-Ressourcenfresser ohne Mehrwert für den Benutzer sind die Indexprogramme "Strigi" und "Baloo" bekannt.
Ein großes Problem ist, daß sich unangenehme Programme immer häufiger mit dem Kernel oder den Desktopumgebungen verzahnen. Eigentlich ermöglicht das rpm-System ein sauberes Deinstallieren von Anwendungen. Dann kann der Benutzer entscheiden, ob er ein bestimmtes Programm verwenden will oder nicht.
Solche verzahnten Programme kann er dagegen nicht loswerden, ohne auf wesentliche Funktionen des Systems (wie z.B. KDE-Programme) zu verzichten.
Es gibt auf der Welt böse Menschen, und die Linux-Welt ist leider keine Ausnahme davon. Der Vorteil des Prinzips der Freien Software ist aber, daß es dann andere Menschen geben wird, die Schadprogramme erkennen und neue Distributionen zusammenstellen werden, die von diesen frei sind. Wenn es nötig wird, wird es also immer wieder Reinigungsprozesse geben.
Ich hoffe, ich konnte einen Eindruck davon vermitteln, was einen erwartet, wenn man sich mit Windows auskennt, aber dann zum ersten Mal versucht, Linux zu benutzen.
Natürlich gibt es noch viel mehr Details. Diese wurden bereits in zahlreichen Linux-Büchern dargestellt.
Es ging mir erstmal darum, einen Überblick zu geben, so daß man sich mit dem System vertraut machen kann, ohne sich dabei in den zahlreichen Einzelheiten zu verlieren.
Ich habe mit Linux die Erfahrung gemacht, daß es zunächst oft nicht macht, was man möchte, aber daß man es nach einiger Zeit wahrscheinlich doch dazu bringen kann, wenn man nur im Internet genug über das jeweilige Thema gelesen hat.
Und immer SuSEs Motto beachten: "Hab' eine Menge Spaß..." ("Have a lot of fun...")

{kind=link}
{kind=link}
{kind=link}